Research
3D Shape Tokenization
We learn a 3D shape representation that is versitile, efficient, and easy to learn. The representation is learned by treating 3D surfaces as probabilistic density functions in 3D and utilizing flow matching to make the density function align with the 3D surfaces. We show that the learned representation can be used in a wide range of applications, including single-image to 3D, zero-shot 3D classification, and neural rendering of normal and depth maps. On all tasks, models based on our representation shows strong performance compared to individual state-of-the-art of each task.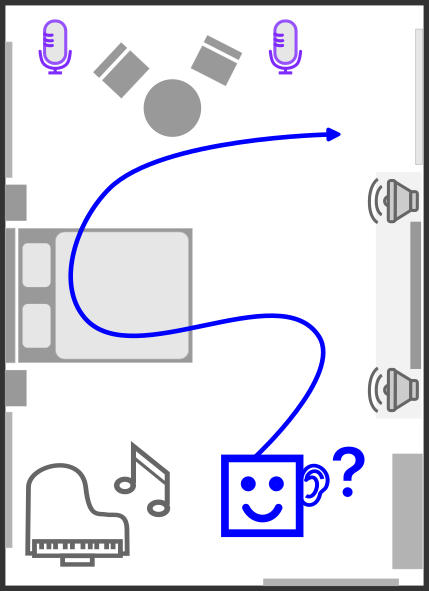
Novel view acoustic synthesis
Novel-view synthesis of images is already a difficult problem; how about novel-view synthesis of sound? The "acoustic camera", i.e., a microphone, has a much lower resolution than photo cameras, and it captures sound from all sound sources, which are echoed differently from the scene. It is a very challenging problem. In this project, we demonstrate we are able to reconstruct the acoustic scene and synthesize spatial audio at any location in a 3d reconstructed scene.
Ray tracining on point clouds
Can we directly perform novel-view synthesis on a scene captured by a depth camera directly without any per-scene optimization? How do we perform ray tracing on a scene represented by point clouds? In this project, we develop a first step toward the goal.
Controllable Generative Models
Can generative models improve recognizers? In this line of works, we develop novel controllable generative models for sequence data (e.g., speech and handwriting) that generates realistic samples, and we demonstrate conditions under which synthetic data significantly benefit downstream recognizers.
Papers accepted by
ICML 2022 (paper 1)
ICASSP 2022 (paper 2, paper 3)

Token Pooling for Vision Transformers
We propose an efficient pooling (token downsampling) algorithm for transformer models. Our analysis shows that softmax attention is a high-dimensional low-pass filter on the input tokens. This means every attention layer produces redundant information. Based on our analysis, we design an algorithm that carefully prunes the redundancy. Simply by inserting our Token Pooling layer after each attention layer, we achieve same accuracy as our baseline models with 40% improvement in compuration cost on ImageNet-1k.
Occlusion-aware Multifocal Displays
Multifocal displays alleviate vergence-accommodation conflict by simultaneously showing contents on transparent focal planes placed at different depths in front of our eyes. Despite its effectiveness to create the accommodation cue, the solution weakens the occlusion cue, because any small movement of our eyes can easily cause content shown on the different focal planes to overlap. The inability for the transparent focal planes to occlude light also significantly reduces the contrast of the virtual world. In the work, we enable occlusion-aware multifocal displays by enabling each display pixels to tilt light. Using a lab prototype, we demonstrate the presence of occlusion cues as well as the increase in the contrast of the display on a range of scenes.
Accepted by SIGGRAPH 2020 (intro video, paper, supplementary)

Toward Multifocal Displays with Dense Focal Stacks
Modern virtual reality displays suffer from the vergence-accommodation conflict, which causes discomfort and fatigue after long duration of usages. While multifocal displays can alleviate the problem, they often have low retinal resolution due to the limited number of focal planes they can generate in a second. In the paper, we present a first-of-its-kind multifocal display that is capable of generating a dense collection of focal planes (an order of magnitude greater in number as compared to prior work). Operating at 1600 focal planes per second, our lab prototype can produce 3D cues even for a single eye and thereby is capable of resolving the vergence-accommodation conflict endemic to today’s VR displays.
Accepted by SIGGRAPH Asia 2018 (intro video, paper, supplementary)

One Network to Solve Them All
A hallmark of state-of-the-art algorithms for linear inverse problems is to train different neural nets for different problems. This becomes very inefficient if we want to incorporate these specially-trained networks into portable devices like cell phones. Cell phone cameras need to deal with a variety of image processing problems, from image deblurring, demosaicing, to super-resolution. To achieve this, we propose a framework that can use a single network to solve any linear inverse problem. This can significantly reduce the cost and complexity of the image signal processor.
Accepted by ICCV 2017 (oral presentation) (intro video, paper, code)
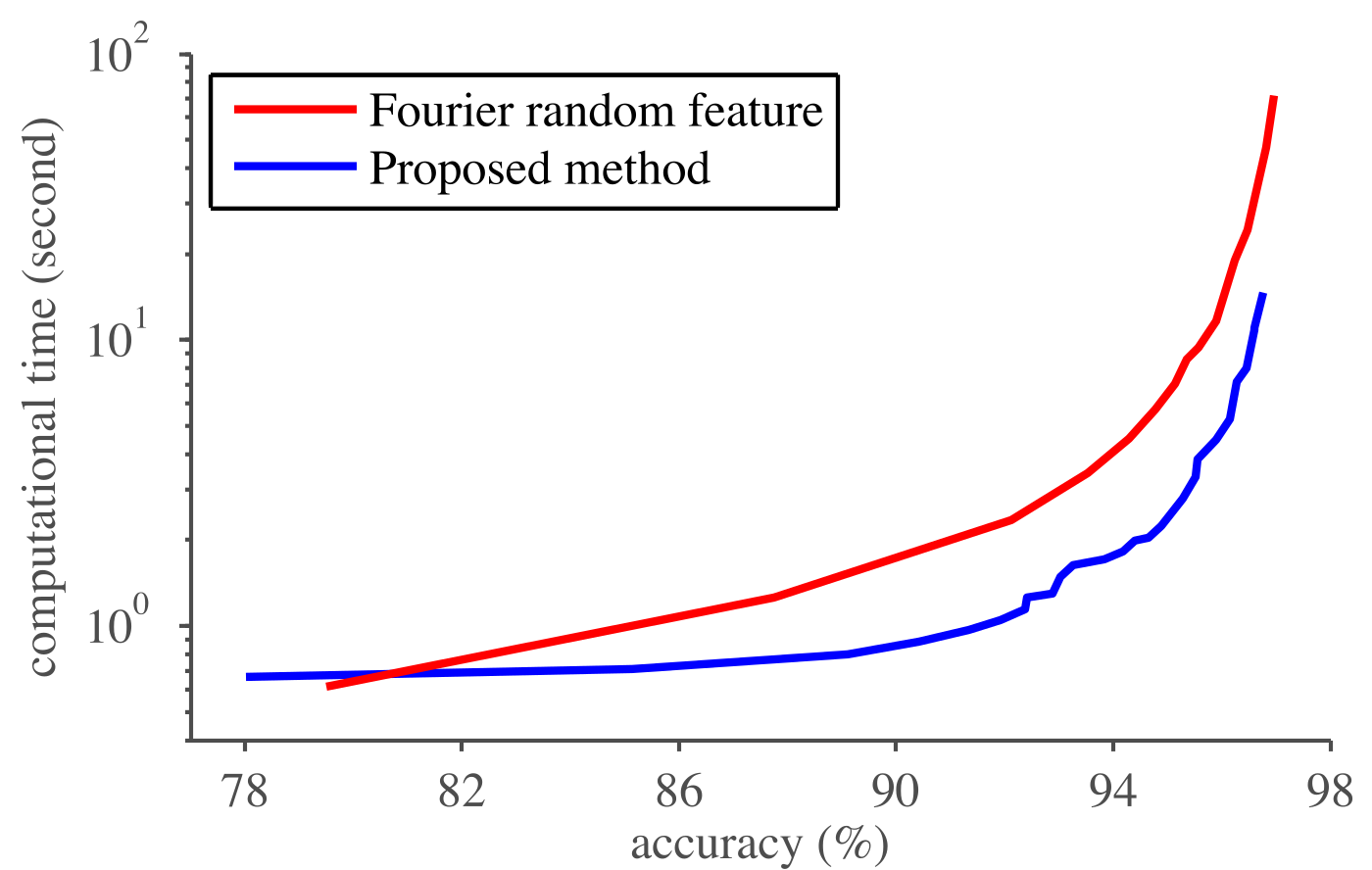
Random feature for sparse signal classification
Despite its ability to approximate almost any decision boundaries, traditional kernel method is difficult to use with large datasets, due to the high memory and computational requirements in both training and test phases. Recent works on random feature have demonstrated promising results of scalable kernel method. In this work, we provide theoretical analyses for random feature on a special yet commonly seen signal class --- sparse signals. It is known that image, video, and speech signals enjoy sparse representations after proper transformation. Our results provide tightened theoretical guarantees for this kind of signals. We also propose compressive random feature, which exploits signal sparsity to reduce data acquisition, memory, and computation requirements for nonlinear classification methods in both training and test phases.
Accepted by CVPR 2016 (spotlight presentation). (paper, code)
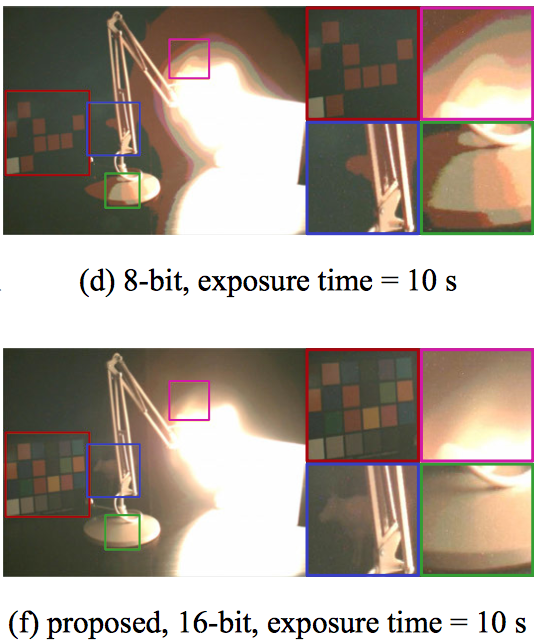
216 Shades of Gray --- High Bit-Depth Projector
While existing projection techniques work well for projecting low bit-depth (8-bit) images, it becomes infeasible for high bit-depth (say, 16-bit) projection --- a capability that is increasingly desirable in many applications including cinemas and gaming. In this paper, we describe a technique for high bit-depth projection using a single light modulator by adopting intensity-modulated light sources. The proposed design involves only a minor modification to traditional projector designs, namely intensity modulation of the light sources, and hence, can be adopted widely by both traditional low bit-depth projectors and modern high dynamic-range projectors. Finally, we present a prototype to showcase and validate the performance of the proposed design.
Accepted by Optics Express, 2016. (paper)

Propagated image filtering
When smoothing an image, we usually want to eliminate noise or wrinkles without losing image contexts (e.g., edges, textures, or important details).Our propagation image filters are designed exactly for this purpose --- context preserving image smoothing.
Accepted by CVPR 2015. (paper, supplement, poster, code)
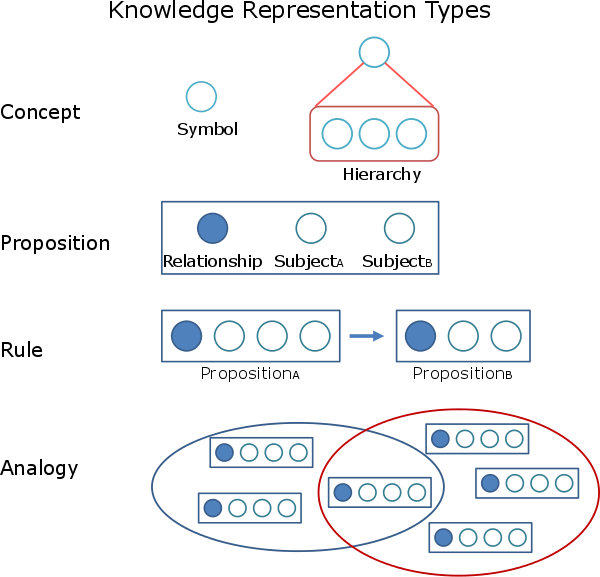
Research on a Learning Model Presuming Representationalism, Functionalism, and Neural Darwinism
The human mind is a fascinating learning machine, which can solve a variety of problems with slightest prior knowledge. While neural network methods have demonstrated huge improvement on problem solving, the mystery of human mind is still waiting to be unraveled. Here, I study the human mind from a different angle by utilizing three complementary hypotheses about the human mind from cognitive science. Specifically, I design and analyze a learning system that mimics human mind with context-free language.
This is my M.S. thesis. The short version is here.
The slides are here.
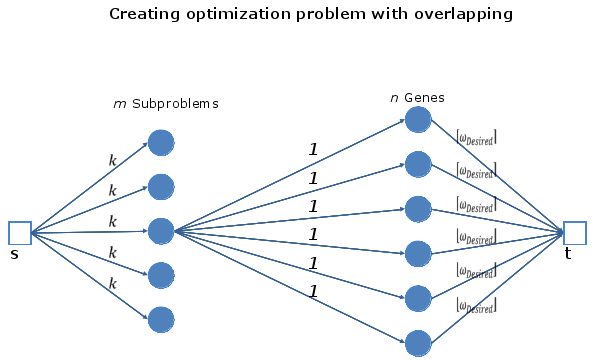
A Test Function with Full Controllability Over Overlapping
While genetic algorithms work well on simple non-convex problems, it has been shown that they may fail on problems which contains complex inter-dependencies between variables.Our work provides an useful tool for analyzing the performance of genetic algorithms on this kind of complex problem. Specifically, we design a standardized test function to generate complex problems with controlled variable dependencies.
Accepted by ACM Genetic and Evolutionary Computation Conference (GECCO) 2011 (pdf).
Other projects
Dependency-Constrained Earth Movers' Distance
The earth movers' distance measures the distance between two sets of points or histograms by solving the transportation problem. Suppose there are cargoes to transport from source nodes to target nodes. Given the weights of these cargoes and the distances between all source-target pairs. The earth movers' distance calculates the minimum cost to transport these cargoes. However, the earth movers' distance ignores the dependencies among these cargoes or points, and related source points may be transported to unrelated target points. We tackle the transportation problem with cargo dependencies and provide more accurate distance measurement when data dependencies exist. We use the proposed more accurate distance metric to improve computer vision applications, including image retrieval, color transfer.
Message Passing Model Building Genetic Algorithm
The simple genetic algorithm can be easily paralleled, because all of its operators are local and not dependent on the whole population of candidate solutions. However, when it comes to model building genetic algorithms, identifying variable dependencies from candidate solutions is not a local operator and needs to use information from the whole population. This makes paralleled model building genetic algorithms difficult. In this work, we implement a distributed model building genetic algorithm, in which the model building process is paralleled by exchanging the distribution of each node's population.
Association Rule Mining Genetic Algorithm
We mine association rules from the population of candidate solutions. These association rules are used to preserve high-fitness subsolutions.
Rubik's Cube Solving Robot
We implement a LEGO NXT robot, which can solve the Rubik's cube all by itself, including scanning the cube and preforming actions to the cube.
Pitch and Tempo Detecting FPGA
We realize a FPGA, which detects the pitch and tempo of a music. This work earned the outstanding paper of the InnovateAsia FPGA Workshop and Design Contest 2009.
Electromyography Controlled Toy Race Car
We realize a circuit, which detects electromyography (EMG) signals and uses the signals to control a toy car :D
Store Information Providing iPhone App
We build an iPhone app, in which users can take photos of store's signboards to retrieve information about these stores. We used SIFT as a feature to perform the recognition.
Rule Evolving Agent for the Wumpus World
We design a rule driven agent for the Wumpus world. We study the process of how the agent adapts its belief toward its rules when encounters different situations.
Facial Expression Recognition by Hierarchical Self-Organizing Map
We design a two-level self organizing map to rocognize facial expressions. This algorithm characterizes these expressions into both high-level and low-level terms.
Smart Drug Box
We design and implement the circuit of a smart drug box, which detects whether the drugs have been taken in order to notify patients.